
接到任务检查某政府网站下所有页面的Meta标签是否符合规范,如手动逐个检查需逐个页面查看源码十分麻烦,于是便撰写了个油猴脚本,打开页面展示指定的Meta是否存在以及其值
其原理是先把需检测的Meta标签以数组定义好,在进行数组循环逐个获取Meta标签,最后使用表格展示并写好漂浮等样式,脚本代码如下:
// ==UserScript==
// @name 检查政府网站Meta标签
// @namespace http://www.xueyidian.cn/
// @version 0.1
// @description 内部版本
// @author MacroDa
// @icon https://www.xueyidian.cn/wp-content/uploads/2018/11/2018112902284651.png
// @require https://cdn.jsdelivr.net/npm/jquery@3.2.1/dist/jquery.min.js
// @match *.www.gov.cn/*
// @match *www.gov.cn/*
// @exclude *www.gov.cn/*/admin/*
// @exclude *www.gov.cn/admin/*
// ==/UserScript==
(function() {
'use strict';
var node = document.createElement("div");
var metas = getMeta();
var copyRights = getCopyRight();
var tableHtml = "";
var ulHtml = "";
node.id = "mateChack";
node.className = "mateChack";
for (let i = 0; i < metas.length; i++) {
var trClass = metas[i].exist ? '' : 'bgRed';
var existText = metas[i].exist ? '√' : '×';
tableHtml += '<tr class="' + trClass + '"><td>' + metas[i].name + '</td><td>' + existText + '</td><td>' + metas[i].content + '</td></tr>';
}
for (let j = 0; j < copyRights.length; j++) {
var liClass = copyRights[j].exist ? 'bgGreen' : 'bgRed';
ulHtml += '<li class="' + liClass + '">' + copyRights[j].name + '</li>';
}
node.innerHTML = '<table cellpadding="0" cellspacing="0"><tr><th>名称</th><th>是否存在</th><th>内容</th></tr>' + tableHtml + '<tr><td colspan="3"><ul>' + ulHtml + '</ul></td></tr></table><p>提示:可单击控件任意处关闭</p>';
if (document.querySelector("body")){
document.body.appendChild(node);
} else {
document.documentElement.appendChild(node);
}
node.addEventListener("click",function(){
node.remove();
});
var style = document.createElement("style");
style.type="text/css";
var styleInner = '.mateChack{ position: fixed; z-index: 9999; left: 50%; top: 50%; transform: translate(-50%, -50%); width: 600px; background: rgba(0, 0, 0, .8); padding: 20px 20px 10px; color: #fff; text-align: center; line-height: 1.8; }' +
'.mateChack table{ width: 100%; border-collapse: collapse; table-layout: fixed; }' +
'.mateChack table td,' +
'.mateChack table th{ border: 1px solid #fff; color: #fff; font-size: 14px; line-height: 1.6; text-align: center; padding: 4px 5px; word-wrap: break-word; }' +
'.mateChack table th{ font-weight: bold; background: rgba(255, 255, 255, .2); font-size: 16px; }' +
'.mateChack ul{ font-size: 0; }' +
'.mateChack ul li{ display: inline-block; padding: 0 10px; margin: 5px; font-size: 14px; line-height: 24px; }' +
'.mateChack table .bgRed{ background: rgba(255, 0, 0, .3); }' +
'.mateChack table .bgGreen{ background: rgba(0, 255, 0, .3); }';
style.innerHTML = styleInner;
if(document.querySelector("#mateChack")){
document.querySelector("#mateChack").appendChild(style);
} else {
GM_addStyle(styleInner);
}
function getCopyRight() {
var footHtml = '';
if ($('#footer')) {
footHtml += $('#footer').html();
}
if ($('.footer')) {
footHtml += $('.footer').html();
}
if ($('#footerBox')) {
footHtml += $('#footerBox').html();
}
if ($('.footerBox')) {
footHtml += $('.footerBox').html();
}
if ($('#Footer')) {
footHtml += $('#Footer').html();
}
if ($('.Footer')) {
footHtml += $('.Footer').html();
}
const govCopyRight = [
{
name: "主办单位",
content: /主办|主管主办|主办单位/g,
exist: false
},
{
name: "版权地址",
content: /人民政府|委员会/g,
exist: false
},
{
name: "联系方式",
content: /联系方式|联系电话|电话/g,
exist: false
},
{
name: "网安备案号",
content: /000000001/g,
exist: false
},
{
name: "ICP备案号",
content: /000000001/g,
exist: false
},
{
name: "网站标识码",
content: /000000001/g,
exist: false
},
{
name: "网站地图",
content: /网站地图/g,
exist: false
},
{
name: "政府网站找错",
content: /jiucuo\.png/g,
exist: false
},
{
name: "网站标识",
content: /red\.png/g,
exist: false
}
]
for (let i = 0; i < govCopyRight.length; i++) {
if (footHtml.match(govCopyRight[i].content)) {
govCopyRight[i].exist = true;
}
}
return govCopyRight;
}
function getMeta() {
const metas = document.getElementsByTagName('meta');
const govMetas = [
{
name: "SiteName",
content: null,
exist: false
},
{
name: "SiteDomains",
content: null,
exist: false
},
{
name: "SiteIDCode",
content: null,
exist: false
},
{
name: "ColumnName",
content: null,
exist: false
},
{
name: "ColumnDescription",
content: null,
exist: false
},
{
name: "ColumnKeywords",
content: null,
exist: false
},
{
name: "ColumnType",
content: null,
exist: false
},
{
name: "ArticleTitle",
content: null,
exist: false
},
{
name: "PubDate",
content: null,
exist: false
},
{
name: "ContentSource",
content: null,
exist: false
},
{
name: "Keywords",
content: null,
exist: false
},
{
name: "Author",
content: null,
exist: false
},
{
name: "Description",
content: null,
exist: false
},
{
name: "Image",
content: null,
exist: false
},
{
name: "Url",
content: null,
exist: false
},
]
for (let i = 0; i < metas.length; i++) {
if (metas[i].getAttribute('name')) {
for (let j = 0; j < govMetas.length; j++) {
if (metas[i].getAttribute('name').toLowerCase() == govMetas[j].name.toLowerCase()) {
govMetas[j].exist = true;
govMetas[j].content = metas[i].getAttribute('content');
}
}
}
}
return govMetas;
}
})();
顶部的@match表示在哪些网址下生效,@exclude则表示排除哪些网站,常用于网站后台地址。
还增加了底部版权规范的检测,可根据实际情况自行调整代码,此脚本效果截图如下:
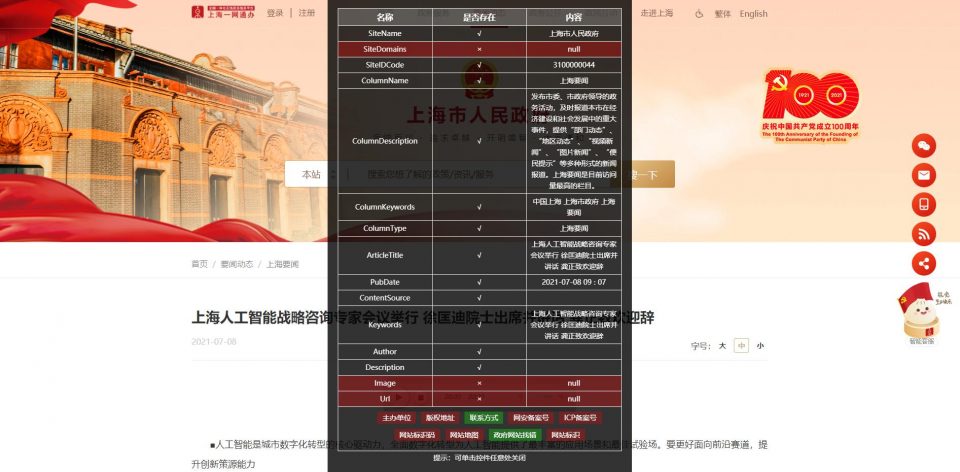
因初次尝试撰写,有很多不足,多多提建议,脚本仅共学习参考